L’arborescence n’est plus un schéma, c’est un système d’autorité
Après plus de 50 audits e-commerce (mode, équipement, mobilier, hygiène pro), un constat revient systématiquement : les plus gros gains SEO ne viennent pas du contenu, mais de la structure.
La majorité des sites web « pénalisés » n’ont pas un problème d’optimisation… mais un problème d’architecture.
Les fuites massives des API internes de Google en 2024 ont confirmé ce que les SEO expérimentés soupçonnaient depuis longtemps :
👉 Google ne note pas seulement vos pages. Il note votre site internet.
Et la manière dont votre arborescence distribue l’autorité interne affecte directement ce score global.
Trois concepts documentés chez Google le confirment :
- siteAuthority : l’autorité agrégée du domaine.
- PageRankPerDocData : chaque lien transmet une partie de l’autorité à une autre page de votre site.
- siteFocusScore : le score de spécialisation thématique du site.
Votre arborescence n’est donc pas une simple organisation :
👉 C’est le système sanguin qui transporte vos signaux d’autorité, de pertinence et de compréhension thématique.
Cette analyse est un guide exhaustif, fondé sur les données publiques, les leaks, et l’expérience terrain.
Il vise à vous équiper d’une méthode reproductible pour concevoir une architecture SEO « future-proof ».
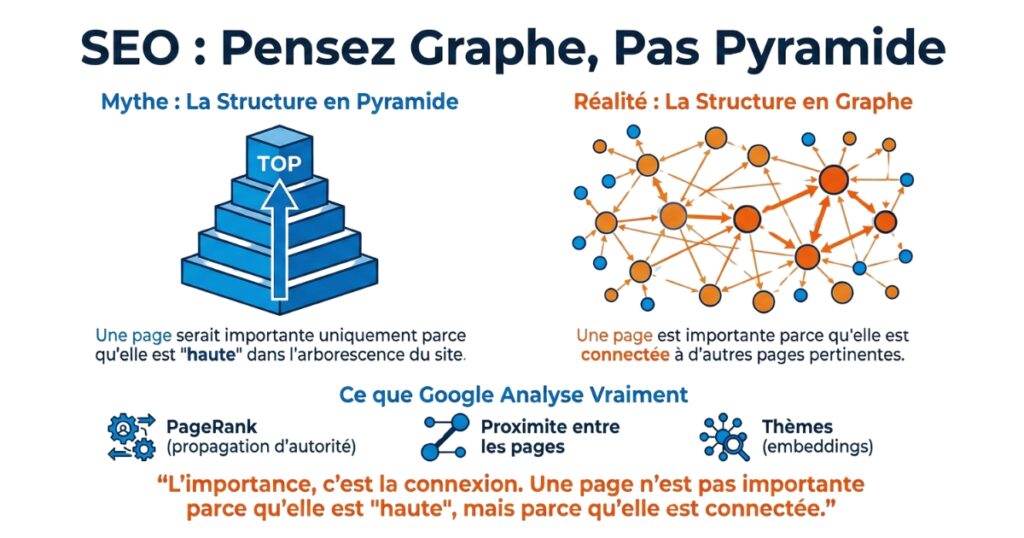
Du modèle pyramidal au modèle graphe
On a longtemps représenté le web comme une pyramide.
Cette vision est selon moi obsolète.
Pourquoi le modèle pyramidal est insuffisant
La pyramide impose :
- une hiérarchie descendante,
- des chemins de navigation uniques,
- un sens de parcours prédéfini.
Or ni les utilisateurs, ni les robots n’empruntent un parcours aussi linéaire sur internet.
Les documents internes révèlent que Google utilise des signaux dérivés du graphe web, pas des hiérarchies figées.
Ce que disent les leaks
Les données montrent clairement comment les moteurs de recherche interprètent et pondèrent les liens internes.
Google stocke pour chaque page :
- des valeurs de propagation dans le graphe (PageRankPerDocData)
- des signaux de proximité entre pages
- des embeddings thématiques (vectorisation du contenu)
Autrement dit :
👉 Une page n’est pas importante parce qu’elle est « haute » dans la pyramide.
Elle est importante parce qu’elle est connectée.
Arborescence, menu, sitemap : trois réalités différentes
L’arborescence : la structure logique interne, invisible, qui organise vos pages.
Le menu : la version UX épurée et choisie.
Attention : le menu n’est pas l’arborescence, et chaque lien visible dilue votre PageRankPerDocData.
Exemple : un mega-menu avec 120 liens divise l’autorité de la page d’accueil par environ 120.
Le sitemap XML : un fichier d’exhaustivité pour robots. N’influence pas la hiérarchie, mais accélère la découverte.
L’arborescence de votre site doit être pensée indépendamment du menu pour distribuer la valeur efficacement.
Le siloing à l’ère du SEO sémantique et la notion de Site Focus Score
L’objectif du Siloing n’est plus seulement la clarté UX.
Les API leaks apportent un éclairage critique :
Le siteFocusScore (Google leak)
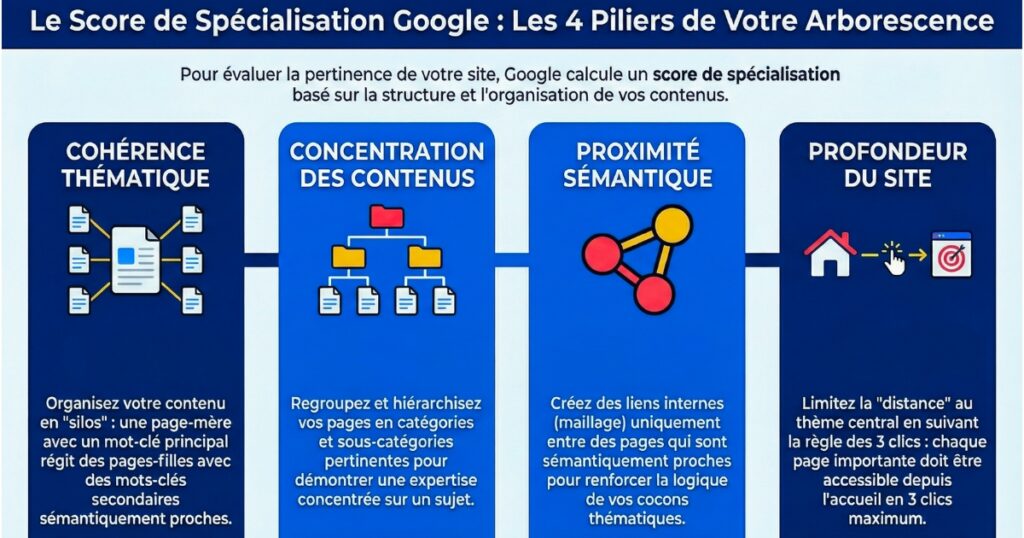
Google calcule pour chaque domaine un score de spécialisation basé sur :
- la cohérence thématique,
- la concentration des contenus,
- la distance sémantique entre pages (embedding vectors),
- le siteRadius : la « distance » entre la thématique centrale et les sujets explorés.
Ce qu’implique le siteRadius
Un site trop dispersé thématiquement augmente son radius → Google le considère comme généraliste → faible expertise → moins de visibilité.
Le rôle du siloing
En créant des silos thématiques étanches, vous :
- renforcez la cohérence sémantique interne,
- augmentez le siteFocusScore,
- limitez la dispersion du siteRadius,
- améliorez la compréhension du graphe par Google.
La méthode du maillage contextuel inversé (MCI) pour votre site web
Cette méthode est conçue pour maximiser la compréhension sémantique du site tout en optimisant la distribution de l’autorité.
Elle se déroule en 6 étapes.
Étape 1 : extraction des intentions dominantes
Analyse sémantique par intentions (info > commerciale > transactionnelle) + clustering.
Étape 2 : regroupement sémantique automatique
Utilisation d’un clustering vectoriel (embedding) pour regrouper les contenus par proximité réelle.
Étape 3 : cartographie « inversée »
Au lieu de partir de la home, on part :
👉 des pages les plus profondes
👉 des produits
👉 des contenus longs
→ et on remonte vers le général.
Objectif : éviter les silos artificiels.
Étape 4 : création du squelette (3 niveaux max)
Niveau 1 : univers (3 à 7 maximum)
Niveau 2 : sous-univers
Niveau 3 : catégories profondes
Profondeur optimale : < 3 clics dans 90% des cas.
Étape 5 : maillage contextuel
Chaque page pointe vers :
- son parent direct,
- ses sœurs,
- 1 page « pilier »,
- 1 page “contextuelle transverse” dans le même silo.
Étape 6 : filtrage & facettes
Attributs indexables : 5 à 10 max si pertinent.
Le reste : noindex + obfuscation pour préserver le crawl budget.
L’objectif de la méthode est de créer une bonne arborescence qui maximise la propagation d’autorité.
Optimisation du crawl budget, précepte essentiel pour les sites volumineux
Les leaks confirment que Google garde un historique par URL (Chrome Views, Link Graph Signals, Host Signals).
Pour les gros sites (>30k URL), le crawl est un enjeu vital. Google ne crawl pas toutes les pages du site avec la même fréquence : il optimise selon l’historique et la valeur perçue.
Voici les techniques avancées :
✔ Obfuscation des liens non prioritaires, ex : facets « couleur », « tri » → cloaking JS.
✔ Canonicalisation stricte : une URL ≠ un contenu ≠ un titre ≠ une finalité.
✔ Menus minimisés : moins de liens = plus de PageRank par lien.
✔ Pruning (désactivation contrôlée) : dépublication / 410 des pages zombies.
✔ Rebond vers pages à forte valeur, maillage automatique vers :
- les best sellers
- les catégories centrales
- les pages piliers
Les pièges expliqués avec les signaux Navboost
Les documents internes confirment que Google utilise les données comportementales (Chrome + Search interactions).
Navboost + pogo-sticking = mort lente assurée
La mécanique :
- L’utilisateur clique sur votre site.
- Il ne trouve pas ce qu’il cherche.
- Il revient en arrière (signal négatif = bad click).
- Google baisse votre score comportemental.
- Votre page descend.
Une mauvaise arborescence → mauvaise orientation → détérioration de l’expérience utilisateur → bad clicks → dégradation Navboost.
Mega-menus → dilution de PageRank
Exemple : un mega-menu avec 120 liens sortants = autorité de la home divisée par 120.
Un site bien structuré facilite la compréhension de Google et améliore la distribution du PageRank interne
La checklist « arborescence SEO 2026 » pour un site internet !
- Profondeur maximale < 3 pour 90% des pages
- Fil d’Ariane avec Schema.org
- Siloing strict
- Mega-menu ≤ 25 liens
- Facettes non indexables + obfuscation JS
- Pages piliers créées par silo
- URL courtes + descriptives
- Maillage contextuel (parent, siblings, pilier, transverse)
- Pruning trimestriel
- Template de navigation identique sur tout le site
Le SEO structurel est l’avantage compétitif le plus sous-exploité
Avec les révélations des API Google et la montée en puissance de l’IA générationnelle, la structure n’est plus un avantage… c’est un prérequis.
Une bonne arborescence améliore simultanément l’autorité, la lisibilité et les signaux comportementaux.
Une arborescence maîtrisée :
- distribue mieux votre siteAuthority,
- clarifie votre siteFocusScore,
- réduit les bad clicks,
- démultiplie le crawl,
- crée un graphe sémantique lisible,
- transforme chaque contenu en amplificateur.
C’est le seul levier qui :
👉 augmente la visibilité,
👉 améliore l’UX,
👉 et renforce votre expertise thématique.










